All information in SQL Server is stored at the page level. The page
is the smallest level of I/O in SQL Server and is the fundamental
storage unit. Pages contain the data itself or information about the
physical layout of the data. The page size is the same for all page
types: 8KB, or 8,192 bytes. The pages are arranged in two basic types of
storage structures: linked data pages and index trees.
Databases are divided into logical 8KB pages. Within
each file allocated to a database, the pages are numbered contiguously
from 0 to n. The actual number of pages
in the database file depends on the size of the file. Pages in a
database are uniquely referenced by specifying the database ID, the file
ID for the file the page resides in, and the page number within the
file. When you expand a database with ALTER DATABASE, the new
space is added at the end of the file, and the page numbers continue
incrementing from the previous last page in the file. If you add a
completely new file, its first page number is 0. When you shrink a
database, pages are removed from the end of the file only, starting at
the highest page in the database and moving toward lower-numbered pages
until the database reaches the specified size or a used page that cannot
be removed. This ensures that page numbers within a file are always
contiguous.
1. Page Types
There are eight page types in SQL Server, as listed in Table 1.
Table . Page Types
| Page Type | Stores |
|---|
| Data | Data rows for all data except text, ntext, image, nvarchar(max), varchar(max), varbinary(max), and xml data |
| Row Overflow | Data columns that cause a data row to exceed the 8,060 bytes per page limit |
| LOB | Large object types (text, ntext, image, nvarchar(max), varchar(max), varbinary(max), xml data, and varchar, nvarchar, varbinary, and sqlvariant when data row size exceeds 8KB) |
| Index | Index entries and pointers |
| Global Allocation Map | Information about allocated (used) extents |
| Page Free Space | Information about page allocation and free space on pages |
| Index Allocation Map | Information about extents used by a table or an index |
| Differential Changed Map | Information about which extents have been modified since the last full database backup |
| Bulk Changed Map | Information about which extents have been used in a minimally logged or bulk-logged operation since the last BACKUP LOG statement |
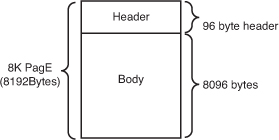
All pages, regardless of type, have a similar layout.
They all have a page header, which is 96 bytes, and a body, which
consequently is 8,096 bytes. The page layout is shown in Figure 1.
2. Data Pages
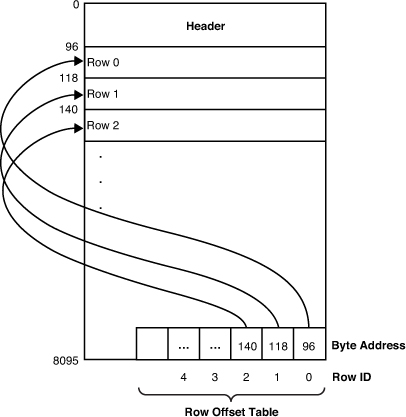
The actual data rows in tables are stored on data pages. Figure 2 shows the basic structure of a data page.
The following sections discuss and examine the contents of the data page.
The Page Header
The page header
contains control information for the page. Some fields assist when SQL
Server checks for consistency among its storage structures, and some
fields are used when navigating among the pages that constitute a table.
Table 1 describes the more useful fields contained in the page header.
Table 1. Information Contained in the Page Header
| Page Header Fields | Description |
|---|
| PageID | Unique identifier for the page. It consists of two parts: the file ID number and page number. |
| NextPage | File number and page number of the next page in the chain (0 if the page is the last or only page in the chain or if the page belongs to a heap table). |
| PrevPage | File number and page number of the previous page in the chain (0 if the page is the first or only page in the chain or if the page belongs to a heap table). |
| ObjectID | ID of the object to which this page belongs. |
| PartitionID | ID of the partition of which this page is a part. |
| AllocUnitID | ID of the allocation unit that contains this page. |
| LSN | Log sequence number (LSN) value used for changes and updates to this page. |
| SlotCnt | Total number of rows (slots) used on the page. |
| Level | Level at which this page resides in an index tree (0 indicates a leaf page or data page). |
| IndexID | ID of the index this page belongs to (0 indicates that it is a data page). |
| freedata | Byte offset where the available free space starts on the page. |
| Pminlen | Minimum size of a data row. Essentially, this is the number of bytes in the fixed-length portion of the data rows. |
| FreeCnt | Number of free bytes available on the page. |
| reservedCnt | Number of bytes reserved by all transactions. |
| Xactreserved | Number of bytes reserved by the most recently started transaction. |
| tornBits | Bit string containing 1 bit per sector for detecting torn page writes (or checksum information if torn_page_detection is not on). |
| flagBits | Two-byte bitmap that contains additional information about the page. |
The Data Rows
Following the page header, starting at byte 96 on the
page, are the actual data rows. Each data row has a unique row number
within the page. Data rows in SQL Server cannot cross page boundaries.
The maximum available space in a SQL Server page is 8,060 bytes of
in-row data. When a data row is logged in the transaction log (for an
insert, for example), additional logging information is stored on the
log page along with the data row. Because log pages are 8,192 bytes in
size and also have a 96-byte header, a log page has only 8,096 bytes of
available space. If you want to store the data row and logging
information on a single log page, the in-row data cannot be more than
8,060 bytes in size. This, in effect, limits the maximum in-row data row
size for a table in SQL Server 2008 to 8,060 bytes as well.
Note
Although
8,060 bytes is the maximum size of in-row data, 8,060 bytes is not the
maximum row size limit in SQL Server 2008.
The number of rows stored on a page depends on the
size of each row. For a table that has all fixed-length, non-nullable
columns, the size of the row and the number of rows that can be stored
on a page are always the same. If the table has any variable or nullable
fields, the number of rows stored on the page depends on the size of
each row. SQL Server attempts to fit as many rows as possible in a page.
Smaller row sizes allow SQL Server to fit more rows on a page, which
reduces page I/O and allows more data pages to fit in memory. This helps
improve system performance by reducing the number of times SQL Server
has to read data in from disk.
Because each data row also incurs some overhead bytes in addition to the actual data, the maximum amount of actual data
that can be stored in a single row on a page is slightly less than
8,060 bytes. The actual amount of overhead required per row depends on
whether the table contains any variable-length columns. If you attempt
to create a table with a minimum row size including data and row
overhead that exceeds 8,060 bytes, you receive an error message as shown
in the following example (remember that a multibyte character set data
type such as nchar or nvarchar requires 2 bytes per character, so an nchar(4000) column requires 8,000 bytes):
CREATE TABLE customer_info2
(cust_no INT, cust_address NCHAR(25), info NCHAR(4000))
go
Msg 1701, Level 16, State 1, Line 1
Creating or altering table 'customer_info2' failed because the
minimum row size would be 8061, including 7 bytes of internal
overhead. This exceeds the maximum allowable table row size of 8060
bytes.
If the table contains variable-length or nullable
columns, you can create a table for which the minimum row size is less
than 8,060 bytes, but the data rows could conceivably exceed 8,060
bytes. SQL Server allows the table to be created. If you then try to
insert a row that exceeds 8,060 bytes of data and overhead, the data
that exceeds the 8,060-byte limit for in-row data is stored in a
row-overflow page.
The Structure of Data Rows
The data for all fixed-length data fields in a table
is stored at the beginning of the row. All variable-length data columns
are stored after the fixed-length data. Figure 3 shows the structure of the data row in SQL Server.

The total size of each data row is a factor of the
sum of the size of the columns plus the row overhead. Seven bytes of
overhead is the minimum for any data row:
1 byte for status byte A.
1 byte for status byte B (in SQL Server 2008, only 1 bit is used indicating that the record is a ghost-forwarded row).
2 bytes to store the length of the fixed-length columns.
2 bytes to store the number of columns in the row.
1 byte for every multiple of 8 columns (ceiling(numcols / 8) in the table for the NULL bitmap. A 1 in the bitmap indicates that the column allows NULLs.
The values stored in status byte A are as follows:
Bit 0— This bit provides version information. In SQL Server 2008, it’s always 0.
Bits 1 through 3— This 3-bit value indicates the nature of the row. 0 indicates that the row is a primary record, 1 indicates that the row has been forwarded, 2 indicates a forwarded stub, 3 indicates an index record, 4 indicates a blob fragment, 5 indicates a ghost index record, 6
indicates a ghost data record, and 7 indicates a ghost version record.
Bit 4— This bit indicates that a NULL bitmap exists. This is somewhat unnecessary in SQL Server 2008 because a NULL bitmap is always present, even if no NULLs are allowed in the table.
Bit 5— This bit indicates that one or more variable-length columns exists in the row.
Bit 6— This bit indicates the row contains versioning information.
Bit 7— This bit is not currently used in SQL Server 2008.
If the table contains any variable-length columns, the following additional overhead bytes are included in each data row:
2 bytes to store the number of variable-length columns in the row.
2
bytes times the number of variable-length columns for the offset array.
This is essentially a table in the row identifying where each
variable-length column can be found within the variable-length column
block.
Within each block of fixed-length or variable-length
data, the data columns are stored in the column order in which they were
defined when the table was created. In other words, all
fixed-length fields are stored in column ID order in the fixed-length
block, and all nullable or variable-length fields are stored in column
ID order in the variable-length block.
Storage of the sql_variant Data Type
The sql_variant data type can contain a value of any column data type in SQL Server except for text, ntext, image, variable-length columns with the MAX qualifier, and timestamp. For example, a sql_variant in one row could contain character data; in another row, an integer value; and in yet another row, a float value. Because they can contain any type of value, sql_variant columns are always considered variable length. The format of a sql_variant column is as follows:
Byte 1 indicates the actual data type being stored in the sql_variant.
Byte 2 indicates the sql_variant version, which is always 1 in SQL Server 2008.
The remainder of the sql_variant column contains the data value and, for some data types, information about the data value.
The data type value in byte 1 corresponds to the values in the xtype column in the systypes database system table. For example, if the first byte contains a hex 38, that corresponds to the xtype value of 56, which is the int data type.
Some data types stored in a sql_variant column require additional information bytes stored at the beginning of the data value (after the sql_variant version byte). The data types requiring additional information bytes and the values in these information bytes are as follows:
Numeric and decimal data types require 1 byte for the precision and 1 byte for the scale.
Character strings require 2 bytes to store the maximum length and 4 bytes for the collation ID.
Binary and varbinary data values require 2 bytes to store the maximum length.
Storage of Sparse Columns
A new storage feature introduced in SQL Server 2008
is sparse columns. Sparse columns are ordinary columns that use an
optimized storage format for NULL values. Sparse columns reduce the space requirements for NULL values at the cost of more overhead to retrieve non-NULL values. A rule of thumb is to consider using sparse columns when you expect at least 90% of the rows to contain NULL values. Prime candidates are tables that have many columns where most of the attributes are NULL
for most rows—for example, when different attributes apply to different
subsets of rows and, for each row, only a subset of columns are
populated with values.
The sparse columns feature significantly increases
the number of possible columns in a table from 1,024 to 30,000. However,
not all 30,000 can contain values. The number of actual populated
columns you can have depends on the number of bytes of data in the rows.
With sparse columns, storage of NULL values is optimized, requiring no space at all for storing NULL values. This is unlike nonsparse columns, which, as you saw earlier, do need space even for NULL values (a fixed-length NULL value requires the full column width, and a variable-length NULL requires at least 2 bytes of storage in the column offset array).
Although sparse columns themselves require no space for NULL
values, there is some fixed overhead space required to allow rows to
contain sparse columns. This space is needed to add the sparse vector to
the end of the data row. A sparse vector is added to the end of a data
row only if at least one sparse column is defined on the table.
The sparse vector is used to keep track of the
physical storage of sparse columns in the row. It is stored as the last
variable-length column in the row. No bit is stored in the NULL bitmap for the sparse vector column but it is included in the count of the variable columns (refer to Figure 34.3 for the general structure of a data row). The bytes stored in the sparse vector are shown in Table 2.
Table 2. Bytes Stored in the Sparse Vector
| Name | Number of Bytes | Description |
|---|
| Complex column header | 2 | A value of 05 indicates the column is a sparse vector |
| Sparse column count | 2 | Number of sparse columns |
| Column ID set | 2 × # of sparse columns | The column IDs of each column with a value stored in the sparse vector |
| Column offset table | 2 × # of sparse columns | The offset of the ending position of each sparse column |
| Sparse data | Depends on actual values | The actual data values for each sparse column stored in column ID order |
With the required overhead space for the sparse vector, the maximum size of all fixed-length non-NULL sparse columns is reduced to 8,019 bytes per row.
As you can see, the contents of a sparse vector are like a data row structure within a data row. If you refer to Figure 3,
you can see that the structure of the sparse vector is similar to the
shaded structure of a data row. One of the main differences is that the
sparse vector stores no information for any sparse columns that contain NULL
values. Also, fixed-length and variable-length columns are stored the
same within the sparse vector. However, if you have any variable-length
columns in the sparse vector that are too large to fit in the 8,019-byte
limit of the data row, they are stored on row-overflow pages.
The Row Offset Table
The location of a row within a page is identified by the row offset table,
which is located at the end of the page. To find a specific row within a
page, SQL Server looks up the starting byte address for a given row ID
in the row offset table, which contains the offset of the row from the
beginning of the page (refer to Figure 2).
Each entry in the row offset table is 2 bytes in size, so for each row
in a table, an additional 2 bytes of space is added in from the end of
the page for the row offset entry.
The
row offset table keeps track of the logical order of rows on a data
page. If a table has a clustered index defined on it, the data rows are
stored in clustered index order. However, they may not be physically
stored in clustered key order on the page itself. Instead, the row
offset array indicates the logical clustered key order of the data rows.
For example, row offset slot 0 refers to the first row in the clustered
index key order, slot 1 refers to the second row, slot 2 refers to the
third row, and so on. The physical location of the rows on the page may
be in any order, depending on when rows on the page were inserted or
deleted.